Chapter 1: DBMS
Introduction
Data
Data refers to raw, unprocessed facts and figures collected from various sources. It has no meaning on its own and requires context to become useful. Examples include numbers, names, dates, and measurements.
Information
Information is data that has been processed, organized, or structured in a way that adds meaning and makes it useful for decision-making. It helps individuals and organizations make informed choices based on facts.
Database
A database is a structured collection of related data that is stored electronically and can be accessed, managed, and updated easily. It allows for efficient storage, retrieval, and organization of large amounts of data.
Purpose of Database
The purpose of a database is to provide a systematic and organized way to store, manage, and retrieve data efficiently. It helps reduce data redundancy, ensures consistency, and supports multiple users in accessing data securely and concurrently.
DBMS
Definition
A DBMS (DataBase Management System) is software that interacts with users, applications, and the database itself to store, retrieve, and manage data efficiently and securely.
Features of DBMS
- Data Integrity: Ensures accuracy and consistency of data.
- Security: Restricts unauthorized access to data.
- Backup & Recovery: Supports automatic data backup and restore mechanisms.
- Concurrency: Allows multiple users to access data simultaneously without conflicts.
- Data Independence: Applications remain unaffected by changes in database structure.
Advantages of DBMS
- Centralized Control: Manages data centrally for better consistency.
- Data Sharing: Multiple users can share data concurrently.
- Minimized Redundancy: Eliminates duplication of data.
- Easy Querying: Provides powerful query languages like SQL.
- Better Security: Offers role-based access control.
Disadvantages of DBMS
- Costly Setup: Initial installation and licensing can be expensive.
- Complexity: Requires skilled personnel to manage.
- Hardware Demands: Needs high-performance systems for large databases.
- Data Corruption Risk: A failure can affect the entire system.
- Frequent Maintenance: Regular updates and maintenance are essential.
Common Terminologies Related to DBMS
- Table: A table stores data in rows and columns. It represents a specific topic or entity, like students or books. Each row is a record, and each column is a field.
- Field: A field is a column in a table that stores one type of data, like a name or ID. All records in the table have the same fields.
- Record: A record is a row in a table that contains data about one item. For example, all details about one student form a record.
- Tuple: A tuple is another word for a record in a relational database. It refers to one complete row in a table.
- Objects: Objects combine data and actions in one unit. They are used in object-oriented databases to represent real-world entities.
- Keys: Keys are fields that uniquely identify records or link tables. Common types are primary keys and foreign keys.
- Data Dictionary: A data dictionary stores definitions and details of all data elements in the database. It helps manage the structure and rules of the database.
Types of Database
Hierarchical Model
The hierarchical model organizes data in a tree-like structure where each child record has only one parent, forming a strict one-to-many relationship. It is often used in applications with clearly defined parent-child relationships, such as organizational charts or file systems. This model enables fast access to data and simplifies referential integrity. The structure resembles a tree with branches, making it efficient for traversing fixed, predictable paths of information.
Advantages:
- High performance for queries on hierarchical relationships
- Data integrity is strongly maintained through the tree structure
Network Model
The network model allows more flexible relationships by supporting many-to-many links between records. It organizes data as records connected by links, forming a graph structure instead of a strict hierarchy. This model is effective for complex applications like telecommunications or transport systems, where entities may relate to multiple other entities. It reflects a mesh-like structure, enabling more dynamic and interconnected data paths.
Advantages:
- Supports complex relationships and data access paths
- Efficient for handling large networks of related data
Relational Model
The relational model stores data in tables (relations), where each row represents a record and each column corresponds to a field. This model is the most widely used due to its simplicity, flexibility, and use of SQL for querying. It relies on keys to manage relationships and ensures data accuracy through normalization and constraints. Much like a structured ledger or spreadsheet, it allows for logical organization of diverse data sets in an accessible format.
Advantages:
- Easy to understand and implement using standard query languages
- Ensures data accuracy and reduces redundancy through normalization
Entity-Relational Model
The E-R model is a high-level conceptual data model that illustrates entities (objects) and the relationships between them. It is primarily used in the database design phase to map out how data components interact before implementing the structure in a relational model. By representing data through diagrams, it helps identify logical groupings and associations. The model functions similarly to a blueprint in architecture, offering a clear representation of the data environment before construction.
Advantages:
- Facilitates clear planning of complex data structures
- Enhances communication between developers and stakeholders during design
Integrity Constraints and Types
Integrity constraints are rules applied to database data to ensure accuracy, consistency, and validity throughout its lifecycle. They prevent invalid data entry and maintain reliable relationships between tables.
Domain Constraint
This restricts the type, format, and range of values that a field (attribute) can hold. For example, a "Date of Birth" field must contain valid dates only, ensuring data falls within a specific domain.
Entity Integrity Constraint
This ensures that every table has a primary key and that the primary key values are unique and not null. It guarantees that each record (entity) can be uniquely identified within a table.
Referential Integrity Constraint
This maintains consistency among related tables by ensuring that a foreign key value always points to an existing primary key value in the referenced table. It prevents orphan records and keeps relationships valid.
Key Constraints
Key constraints define one or more attributes as keys to uniquely identify tuples in a relation. Primary keys uniquely identify records, while candidate keys are potential primary keys, and alternate keys are candidate keys not chosen as primary.
Normalization
Normalization is a database design technique used to organize data to reduce redundancy and improve data integrity. It involves dividing large tables into smaller, related tables and defining relationships between them to ensure efficient data management.
Normal Forms
Normalization is carried out through a series of rules called normal forms, each with specific criteria to refine the database structure.
1NF (First Normal Form)
A table is in 1NF when all its columns contain atomic (indivisible) values, and each record is unique. It eliminates repeating groups and ensures that each field contains only one value.
2NF (Second Normal Form)
A table is in 2NF if it is in 1NF and all non-key attributes are fully functionally dependent on the primary key. This removes partial dependency, meaning no column depends on just part of a composite key.
3NF (Third Normal Form)
A table is in 3NF if it is in 2NF and all attributes are only dependent on the primary key, not on other non-key attributes. This eliminates transitive dependencies to further reduce redundancy.
Advantages
- Reduces data duplication, leading to efficient storage
- Improves data consistency and integrity
- Simplifies maintenance and updates by minimizing anomalies
Disadvantages
- Increased number of tables can lead to more complex queries
- May reduce performance due to multiple table joins
- Designing fully normalized databases requires careful planning and expertise
Centralized and Distributed Database
Centralized Database
A centralized database is stored and managed in a single location, typically on a central server. All users access the database through this server, ensuring data consistency and security. It simplifies management but can become a bottleneck if many users access it simultaneously.
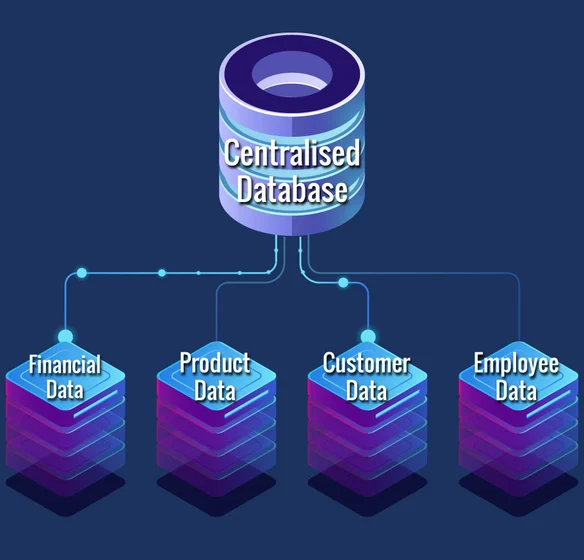
Advantages:
- Easier to manage and maintain due to a single data location
- Simplified security and backup processes
- Lower costs for hardware and infrastructure
Disadvantages:
- Single point of failure risks data loss or downtime
- Limited scalability for large or global organizations
- Potential performance bottlenecks under heavy load
Distributed Database
A distributed database is spread across multiple locations or servers, allowing data to be stored and processed closer to where it is needed. Each site can operate independently, but they are interconnected to provide a unified view of the data. This model enhances performance and reliability by distributing the workload.
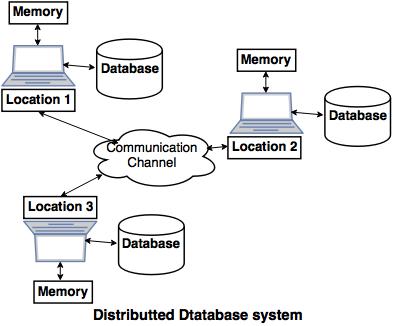
Advantages:
- Improved reliability and availability through data replication
- Faster access for users by storing data closer to their location
- Scalability to handle larger, geographically dispersed systems
Disadvantages
- More complex to design, implement, and manage
- Requires sophisticated synchronization and consistency controls
- Higher costs due to distributed hardware and network infrastructure
Comparison Between Centralized and Distributed Database
| Aspect | Centralized Database | Distributed Database |
|---|---|---|
| Data Location | Single physical location | Multiple physical locations |
| Maintenance | Simpler, centralized management | Complex, requires coordination |
| Reliability | Vulnerable to single point failure | Higher fault tolerance through redundancy |
| Performance | May slow down under heavy load | Faster localized access for users |
| Cost | Lower hardware and network costs | Higher infrastructure and maintenance costs |
Database Security
Database security refers to the processes, policies, and technologies used to protect database systems from unauthorized access, misuse, or breaches. It ensures that sensitive data remains confidential, maintains its integrity, and is available when needed.
Challenges:
- Unauthorized Access: Preventing access by users without proper credentials
- SQL Injection: Protecting against malicious code inserted into queries
- Data Leakage: Avoiding unintended exposure of confidential data
- Insider Threats: Managing access even among trusted employees
- Backup Vulnerabilities: Ensuring stored backups are also secure from tampering
Security Measures:
- Authentication & Authorization: Verifying user identity and assigning appropriate access levels
- Encryption: Securing data during storage and transmission using cryptographic techniques
- Firewalls & Network Controls: Protecting database servers from external threats
- Audit Trails: Keeping logs of user activity to monitor suspicious behavior
- Regular Updates: Applying patches to fix vulnerabilities in DBMS software
Roles of DataBase Administrator (DBA):
- Access Control: Defining and managing user permissions and roles
- Monitoring Security Logs: Continuously reviewing activity logs for anomalies
- Backup & Recovery: Ensuring reliable and secure backups for disaster recovery
- Patch Management: Updating database software to prevent exploitation
- Policy Enforcement: Implementing security policies and compliance standards
ER Diagrams
An ER diagram (Entity-Relationship Diagram) is a visual tool used to model and represent the logical structure of a database by illustrating entities (data objects), their attributes (properties), and the relationships between them. It helps database designers understand complex data structures, plan tables, and ensure that data requirements are met before implementation.
Entity
Definition:
A real-world object or thing (person, place, object, event) that can be distinctly identified. Example: Student, Car, Book.
Symbol:
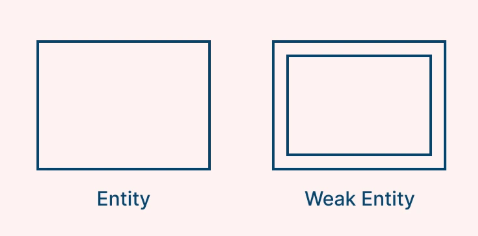
Attributes
Definition:
Properties or characteristics that describe an entity. Example: Student entity might have attributes like Name, ID, Age.
Symbol:
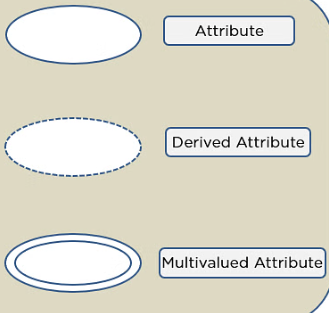
Relationships
Definition:
Association between two or more entities. Example: “Enrolls” relationship between Student and Course entities.
Symbol:
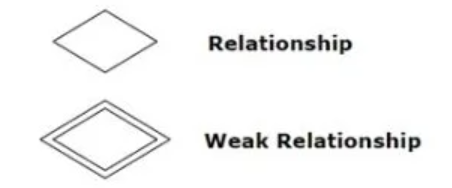
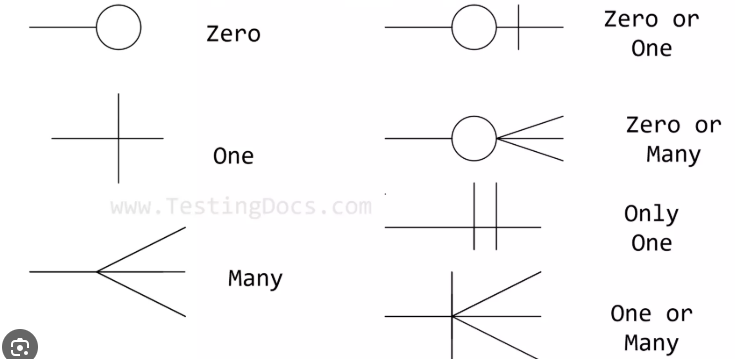
Cardinality
Definition:
Specifies the number of instances of one entity that can or must be associated with instances of another entity. Example: A student can enroll in many courses (1:N).
Symbol
Degree
Definition:
The number of entities involved in a relationship. Example:
- Unary (degree 1): relationship with itself
- Binary (degree 2): most common, between two entities
- Ternary (degree 3): between three entities
Questions and Answers
1. What is data in the context of a DBMS?
Data refers to raw, unprocessed facts and figures such as numbers, names, or dates. In a DBMS, data is stored in structured formats to be organized and made meaningful through processing.
2. How does information differ from data?
Information is processed data that has been structured and given context to be useful. Unlike raw data, information helps in decision-making and provides meaningful insights.
3. What is a database?
A database is an organized collection of related data stored electronically. It allows for efficient storage, retrieval, and management of data using database software.
4. What are the main features of a DBMS?
- Ensures data integrity and consistency
- Provides security against unauthorized access
- Supports backup and recovery
- Allows concurrent data access
- Maintains data independence
5. List two advantages and two disadvantages of using a DBMS.
Advantages:
- Centralized data management
- Reduced data redundancy
Disadvantages:
- High initial setup cost
- Requires regular maintenance and skilled personnel
6. What is a relational database model?
The relational model organizes data into tables, where each table consists of rows (records) and columns (fields). It is widely used due to its simplicity, flexibility, and support for SQL-based queries.
7. Define primary key and foreign key.
Primary Key: A field (or combination of fields) that uniquely identifies each record in a table.
Foreign Key: A field in one table that refers to the primary key of another table, establishing a relationship between the two tables.
8. What is normalization? List its first three normal forms.
Normalization is a design process used to organize data in a database to minimize redundancy and improve integrity. The first three normal forms are:
- 1NF: Eliminates repeating groups and ensures atomicity.
- 2NF: Removes partial dependencies on composite primary keys.
- 3NF: Eliminates transitive dependencies between non-key attributes.
9. What is the difference between centralized and distributed databases?
Centralized Database: Stored at a single location, easier to manage, but vulnerable to single-point failures.
Distributed Database: Spread across multiple locations, more reliable and scalable, but harder to manage and maintain.
10. What are domain, entity integrity, and referential integrity constraints?
- Domain Constraint: Ensures values fall within a valid range or type.
- Entity Integrity: Requires primary keys to be unique and not null.
- Referential Integrity: Ensures foreign keys correctly reference existing records.
Past NEB Questions
1. What is Database and DBMS? List out the advantages and disadvantages of DBMS.
Database: An organized collection of related data stored electronically in a structured way.
DBMS: A software system that allows users to define, create, maintain, and control access to the database.
Advantages:
- Reduced data redundancy
- Improved data integrity and consistency
- Better data security
- Supports concurrent access
- Provides backup and recovery
Disadvantages:
- High initial setup cost
- Complex to manage
- Requires skilled personnel
- Performance may be affected with large data volume
2. Differentiate between file processing system and DBMS. Give at least four points.
| File Processing System | DBMS |
|---|---|
| Data redundancy is high | Data redundancy is minimized |
| No centralized control over data | Centralized control of data |
| Limited security features | Advanced security and access control |
| Difficult to handle concurrent access | Supports concurrent multi-user access |
3. Explain the different models of DBMS with advantages and disadvantages.
Hierarchical Model: Organizes data in a tree structure with parent-child relationships.
Advantages: Fast access to hierarchical data, simple relationships.
Disadvantages: Inflexible structure, difficult to handle many-to-many relationships.
Network Model: Uses a graph structure with multiple parent-child relationships.
Advantages: Supports complex relationships, efficient for many-to-many connections.
Disadvantages: More complex to design and maintain.
Relational Model: Stores data in tables with rows and columns.
Advantages: Easy to understand, flexible, uses SQL.
Disadvantages: Can be slower with very large datasets due to joins.
4. What is a relational database? How is it different from other database models?
A relational database organizes data into tables (relations) where each record is a row and each attribute is a column. It differs from hierarchical and network models by using simple tabular structures and supporting SQL for flexible querying. Relationships are managed through keys rather than pointers.
5. What is data redundancy? How does DBMS help in reducing it?
Data redundancy is unnecessary duplication of data across files or tables. DBMS reduces redundancy by storing data centrally and normalizing it, so each data item is recorded only once and shared as needed.
6. Write differentiate between centralized and distributed database systems.
| Centralized Database | Distributed Database |
|---|---|
| Stored in a single location | Distributed across multiple locations |
| Easy to manage and secure | More complex management and security |
| Single point of failure | Higher reliability with redundancy |
| May have performance bottlenecks | Improved performance through distribution |
7. Who is Database Administrator (DBA)? What are the major responsibilities of DBA?
A Database Administrator (DBA) is a person responsible for managing, maintaining, and securing the database system.
Major Responsibilities:
- Defining user access permissions
- Monitoring and optimizing database performance
- Ensuring data security and integrity
- Backup and recovery management
- Installing and upgrading DBMS software
8. Define normalization. Explain 1NF, 2NF and 3NF with suitable examples. Explain the normalization process with examples.
Normalization: The process of organizing data to reduce redundancy and improve integrity.
1NF: All attributes have atomic values. For example, splitting a "Phone Numbers" field containing multiple numbers into separate rows.
2NF: No partial dependency on a part of the composite key. For example, separating student and course information if course details depend only on course ID.
3NF: No transitive dependency between non-key attributes. For example, removing a "Department Name" field from an employee table if it's dependent on Department ID, which is already a key.
9. Explain the terms: primary key, foreign key, and candidate key with examples.
Primary Key: A unique identifier for a record. Example: StudentID in a student table.
Foreign Key: A field linking to a primary key in another table. Example: DepartmentID in Employee table referencing Department table.
Candidate Key: Any field or combination of fields that can uniquely identify a record. Example: Email or NationalID could be candidate keys.
10. What is SQL? Explain its components and common functions.
SQL (Structured Query Language): A language used to manage and query relational databases.
Components:
- DDL (Data Definition Language): CREATE, ALTER, DROP
- DML (Data Manipulation Language): SELECT, INSERT, UPDATE, DELETE
- DCL (Data Control Language): GRANT, REVOKE
- TCL (Transaction Control Language): COMMIT, ROLLBACK
Common Functions:
- Querying data using SELECT
- Inserting data with INSERT
- Updating records with UPDATE
- Deleting records using DELETE
- Defining schema with CREATE
11. SQL Commands example
a. Create a table named students with the fields: Id, Name, Class, and Marks.
CREATE TABLE students (
Id INT AUTO_INCREMENT PRIMARY KEY,
Name VARCHAR(50),
Class VARCHAR(10),
Marks INT(3)
);
Output:


b. Insert records into the students table with appropriate values.
INSERT INTO students (Name, Class, Marks) VALUES
('Kamlesh', '12A', 85),
('Anita', '12B', 90),
('Phulkumari', '12C', 78);
('Harke', '12D', 88);
('Prakash', '12E', 92);
Output:

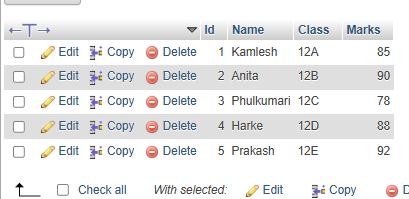
c. Display all records from the students table.
SELECT * FROM students;
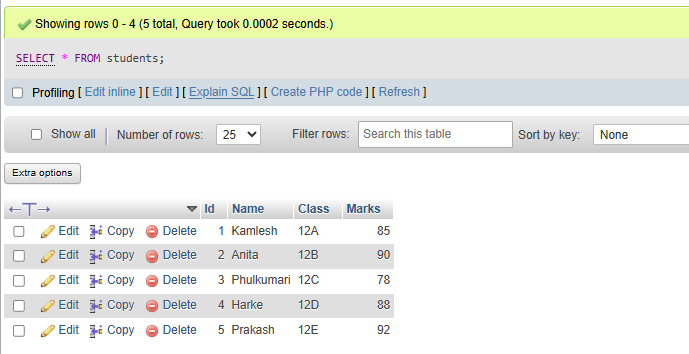
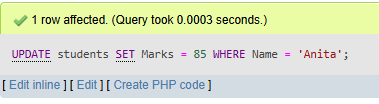
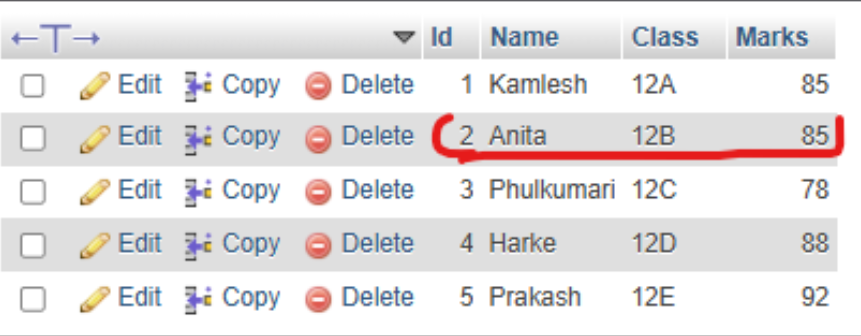
d. Update the marks of a student whose name is 'Anita' to 85.
UPDATE students
SET Marks = 85 WHERE Name = 'Anita';
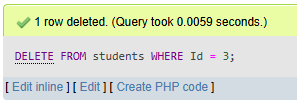
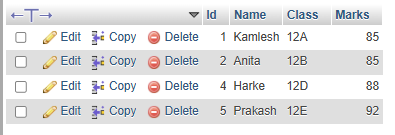
e. Delete the record of the student with id = 3.
DELETE FROM students
WHERE Id = 3;
12. Define the following terms.
a. Data Dictionary
A data dictionary is a collection of metadata that contains definitions and descriptions of data elements, their types, relationships, and constraints used in a database. It acts as a reference guide for users and administrators.
b. Primary Key
A primary key is a unique identifier for each record in a table. It ensures that no duplicate or NULL values exist in the column(s) selected as the primary key.
Example: In a student table, student_id can be a primary key.
c. Relationship
A relationship defines how data in one table is related to data in another table. Common types are one-to-one, one-to-many, and many-to-many relationships.
Example: A student can enroll in multiple courses (one-to-many relationship).
d. Data Manipulation Language (DML)
DML is a subset of SQL used to manipulate data in a database. It includes operations like INSERT, UPDATE, DELETE, and SELECT to work with the actual data.
Example:
SELECT * FROM students;e. Structured Query Language (SQL)
SQL is a standardized language used to manage and manipulate relational databases. It includes commands for data definition, manipulation, and access control.
Example:
CREATE TABLE employees (...);f. Data Integrity
Data integrity refers to the accuracy, consistency, and reliability of data throughout its lifecycle. It ensures data is valid and remains unchanged unless modified through authorized operations.
g. Data Definition Language (DDL)
DDL is a subset of SQL used to define and modify the structure of database objects such as tables and schemas. It includes commands like CREATE, ALTER, and DROP.
Example:
CREATE TABLE students (...);h. Data Security
Data security involves protecting data from unauthorized access, alteration, or deletion. It includes user authentication, encryption, and access control mechanisms to ensure privacy and protection.
i. Database System
A database system is a combination of hardware, software (DBMS), data, and users that work together to store, manage, and retrieve structured data efficiently.